

Die Herstellung von Lebensmitteln ist sehr komplex aufgrund der verschiedenen chemisch-physikalischen und biologischen Prozesse, die bei der Umwandlung von Zutaten in Endprodukte gesteuert werden müssen. Digitale Zwillinge sind aus der Industrie 4.0 als Methode zur Modellierung, Simulation und Optimierung von Prozessen bekannt. In unserem früheren Blogartikel haben wir den aktuellen Stand der Technik bei digitalen „Lebensmittelzwillingen“ und die verbleibenden Herausforderungen auf der Grundlage unserer Literaturanalyse beschrieben [1]. In diesem Artikel stellen wir unsere entsprechende Vision vor.
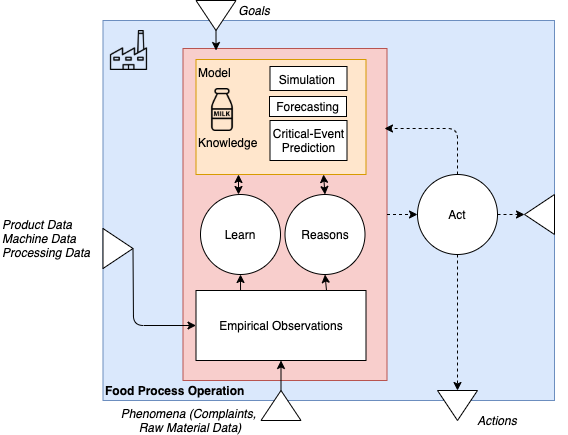
Unser Ansatz ist ein hybrider digitaler Zwilling, der die traditionelle Modellierung/Simulation der biochemischen und physikalischen Lebensmitteleigenschaften (White-Box-Ansatz) mit einer Analyse durch maschinelles Lernen zur Integration spezifischer Informationen (Black-Box-Ansatz) kombiniert. Während sich gängige Industrie 4.0-Ansätze für digitale Zwillinge oft auf die Analyse von Maschinendaten (d.h. die Prozesse) konzentrieren, integriert unser Konzept auch die Simulation der internen Produktzustände.
Integration von Simulation und maschinelles Lernen
Die Notwendigkeit der Produktsicht wollen wir am Beispiel der Joghurtfermentation verdeutlichen. Die Anwendung eines traditionellen digitalen Zwillingskonzepts, wie es aus der Industrie 4.0 bekannt ist, wäre nicht ausreichend, da hier Prozessdaten (hauptsächlich von Maschinen) zur Steuerung der Produktionsprozesse verwendet werden. Ohne Aktionen der Maschinen wird sich der Zustand des Produkts im digitalen Zwilling nicht ändern. Die Joghurtherstellung basiert jedoch auf der Fermentation, das heißt, das Produkt verändert sich während einer schwer zu überwachenden Fermentationsphase nach der Beimpfung mit Starterkulturen. Daher können die Prozessdaten alleine den Prozess nicht ausreichend beschreiben, weil der Prozess innerhalb des Produkts stattfindet. Wenn wir die spärlichen Prozessinformationen mit bekannten Modellen aus der Wissenschaft ergänzen, um das Verhalten der Bakterien zu beschreiben, erhalten wir ein genaueres Bild. Aber auch das Modell selbst würde nach der Beimpfung mit Starterkulturen nicht ausreichen, da das Modell abstrahiert und jede Charge der Starterkultur auch ihre Variationen hat. Das ist ähnlich wie bei der Milch, deren Eigenschaften sich über das Jahr (u.a. aufgrund unterschiedlicher Fütterung) unterscheiden.
Unser digitaler Lebensmittelzwilling bezieht seine Daten aus der Produktionsstätte (d.h. Sensor-, Maschinen- und Verarbeitungsdaten, z.B. Temperatur, Druck oder pH-Wert) und integriert auch Rohstoffdaten und Wissen von Experten (z.B. über die Handhabung von Produktionsproblemen). Unter Verwendung verschiedener Simulationsmethoden, die auf chemisch-physikalischen Modellen und numerischen Simulationen aus der Lebensmittelwissenschaft beruhen, liefert der digitale Zwilling Informationen über die tatsächliche Lebensmittelverarbeitung und unterstützt durch eine Rückmeldung in Echtzeit den Lebensmittelprozessbetrieb.
Nutzung von erklärbarer künstlicher Intelligenz
Zur Konstruktion des digitalen Zwillings wollen wir erklärbare künstliche Intelligenz (XAI) einsetzen. XAI beschäftigt sich mit Methoden und Algorithmen, die dem Menschen Erklärungen liefern, warum eine Entscheidung getroffen wurde. Zwei Ansätze für XAI sind denkbar:
- Einige maschinelle Lernverfahren sind von Natur aus erklärbar, z.B. Entscheidungsbäume oder Random Forest. Diese können jedoch bei großen Datensätzen an ihre Grenzen stoßen und unterstützen keine automatische Merkmalsextraktion, wie es bei Deep-Learning-Methoden der Fall ist.
- Bei nicht erklärbaren Ansätzen wie tiefen neuronalen Netzen besteht die Idee darin, eine zweite Komponente, die XAI-Komponente, einzusetzen, die versucht, die Ergebnisse mit Modellen zu erklären.
Welcher Ansatz sich am besten eignet, ist eine aktuelle Forschungsfrage, mit der wir uns befassen müssen.
Es gibt noch einige offenen Probleme, die gelöst werden müssen, z.B. das Fehlen physikalisch-chemischer Modelle, die Erklärbarkeit der Datenanalyse oder die Validierung der Daten und der wiederverwendbaren Modelle des digitalen Lebensmittelzwillings. Eine vollständige Diskussion der Anwendungsfälle und verbleibenden Herausforderungen finden Sie in unserer Veröffentlichung (mit den Co-Autorinnen Christine Borsum und Tanja Noack) zum Thema [2]. Lesen Sie im dritten Artikel der Serie, wie mit unserem Konzept Anomalien in der Herstellung von Lebensmittel detektiert werden können.
[1] Henrichs, E.; Noack, T.; Pinzon Piedrahita, A. M.; Salem, M. A.; Stolz, J.; Krupitzer, C. (2022): Can a Byte Improve Our Bite? An Analysis of Digital Twins in the Food Industry. In: Sensors, 22(1): 115, https://doi.org/10.3390/s22010115
[2] Krupitzer, C.; Noack, T.; Borsum, C. (2022): Digital Food Twins Combining Data Science and Food Science: System Model, Applications, and Challenges. Processes, 10(9): 1781, https://doi.org/10.3390/pr10091781
[3] Kounev, S. et al. (2017). The Notion of Self-aware Computing. In: Kounev, S.; Kephart, J.; Milenkoski, A.; Zhu, X. (Ed.). Self-Aware Computing Systems. Springer, Cham. https://doi.org/10.1007/978-3-319-47474-8_1